Assumed Density Filtering Methods for Scalable Learning of Bayesian Neural Networks
In this paper, we first rigorously compare the two algorithms and in the process develop several extensions, including a version of EBP for continuous regression problems and a PBP variant for binary classification.
February 12, 2016
Association for the Advancement of Artificial Intelligence (AAAI) 2016
Authors
Soumya Ghosh (Disney Research)
Francesco Marie Delle Fave (Disney Research)
Jonathan Yedidia (Disney Research)

Assumed Density Filtering Methods for Scalable Learning of Bayesian Neural Networks
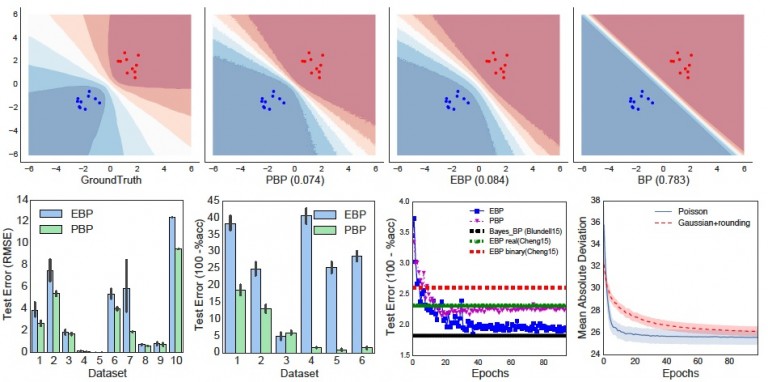
Buoyed by the success of deep multilayer neural networks, there is renewed interest in scalable learning of Bayesian neural networks. Here, we study algorithms that utilize recent advances in Bayesian inference to efficiently learn distributions over network weights. In particular, we focus on recently proposed assumed density filtering based methods for learning Bayesian neural networks – Expectation and Probabilistic backpropagation. Apart from scaling to large datasets, these techniques seamlessly deal with non-differentiable activation functions and provide parameter (learning rate, momentum) free learning. In this paper, we first rigorously compare the two algorithms and in the process develop several extensions, including a version of EBP for continuous regression problems and a PBP variant for binary classification. Next, we extend both algorithms to deal with multiclass classification and count regression problems. On a variety of diverse real-world benchmarks, we find our extensions to be effective, achieving results competitive with the state-of-the-art.