Factorized Variational Autoencoders for Modeling Audience Reactions to Movies
In this paper, we study non-linear tensor factorization methods based on deep variational autoencoders.
July 22, 2017
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017
Authors
Zhiwei Deng (Simon Fraser University)
Rajitha Navarathna (Disney Research)
Peter Carr (Disney Research)
Stephan Mandt (Disney Research)
Ysong Yue (Caltech)
Iain Mathews (Disney Research)
Greg Mori (Simon Fraser University)

Factorized Variational Autoencoders for Modeling Audience Reactions to Movies
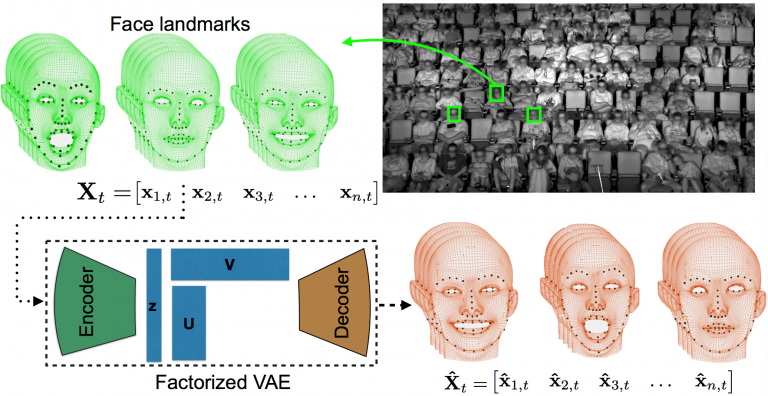
Matrix and tensor factorization methods are often used for finding underlying low-dimensional patterns from noisy data. In this paper, we study non-linear tensor factorization methods based on deep variational autoencoders. Our approach is well-suited for settings where the relationship between the latent representation to be learned and the raw data representation is highly complex. We apply our approach to a large dataset of facial expressions of movie-watching audiences (over 16 million faces). Our experiments show that compared to conventional linear factorization methods, our method achieves better reconstruction of the data, and further discovers interpretable latent factors.