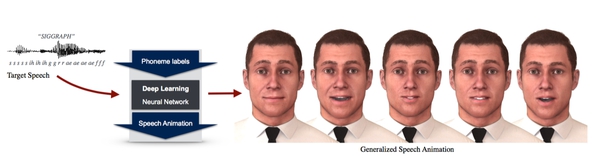
A Deep Learning Approach for Generalized Speech Animation
We introduce a simple and effective deep learning approach to automatically generate natural looking speech animation that synchronizes to input speech.
July 20, 2017
ACM SIGGRAPH 2017
Authors
Sarah Taylor (University of East Anglia)
Taehwan Kim (California Institute of Technology)
Yisong Yue (California Institute of Technology)
Moshe Mahler (Disney Research)
Jimmy Krahe (Disney Research)
Anastasio Garcia Rodrigues (Disney Research)
Jessica Hodgins (Disney Research)
Iain Matthews (Disney Research)

A Deep Learning Approach for Generalized Speech Animation
We introduce a simple and effective deep learning approach to automatically generate natural looking speech animation that synchronizes to input speech. Our approach uses a sliding window predictor that learns arbitrary nonlinear mappings from phoneme label input sequences to mouth movements in a way that accurately captures natural motion and visual coarticulation effects. Our deep learning approach enjoys several attractive properties: it runs in real-time, requires minimal parameter tuning, generalizes well to novel input speech sequences, is easily edited to create stylized and emotional speech, and is compatible with existing animation retargeting approaches. One important focus of our work is to develop an effective approach for speech animation that can be easily integrated into existing production pipelines. We provide a detailed description of our end-to-end approach, including machine learning design decisions. Generalized speech animation results are demonstrated over a wide range of animation clips on a variety of characters and voices, including singing and foreign language input. Our approach can also generate on-demand speech animation in real-time from user speech input.