Semi-situated Learning of Verbal and Nonverbal Content for Repeated Human-Robot Interaction
We present PIP, an agent that crowdsources its own multimodal language behavior using a method we call semi-situated learning.
November 12, 2016
ICMI 2016
Authors
Iolanda Leite (Disney Research)
Andre Pereira (Disney Research)
Allison Funkhouser (Disney Research)
Boyang Albert Li (Disney Research)
Jill Fain Lehman (Disney Research)

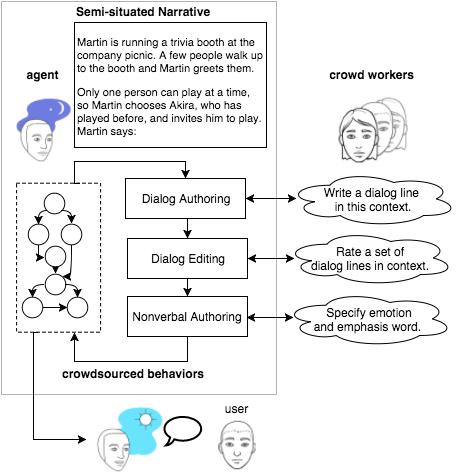
Content authoring of verbal and nonverbal behavior is a limiting factor when developing agents for repeated social interactions with the same user. We present PIP, an agent that crowdsources its own multimodal language behavior using a method we call semi-situated learning. PIP renders segments of its goal graph into brief stories that describe future situations, sends the stories to crowd workers who author and edit a single line of character dialog and its manner of expression, integrates the results into its goal state representation, and then uses the authored lines at similar moments in conversation. We present an initial case study in which the language needed to host a trivia game interaction is learned predeployment and tested in an autonomous system with 200 users “in the wild.” The interaction data suggests that the method generates both meaningful content and variety of expression.