Neural Sequential Phrase Grounding (SeqGROUND)
We propose an end-to-end approach for phrase grounding in images.
June 16, 2019
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019
Authors
Pelin Dogan (Disney Research/ETH Joint PhD)
Leonid Sigal (University of British Columbia/Vector Institute)
Markus Gross (Disney Research/ETH Zurich)
Neural Sequential Phrase Grounding (SeqGROUND)
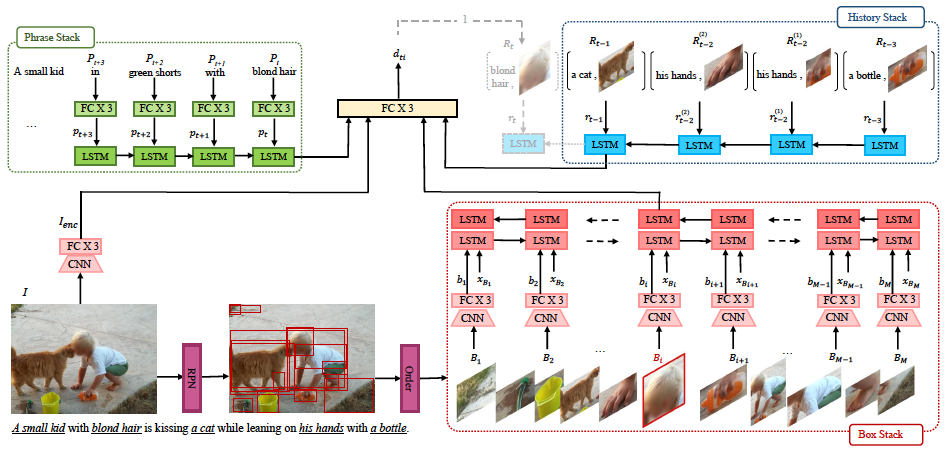
We propose an end-to-end approach for phrase grounding in images. Unlike prior methods that typically attempt to ground each phrase independently by building an image-text embedding, our architecture formulates grounding of multiple phrases as a sequential and contextual process. Specifically, we encode region proposals and all phrases into two stacks of LSTM cells, along with so-far grounded phrase-region pairs. These LSTM stacks collectively capture context for grounding of the next phrase. The resulting architecture, which we call SeqGROUND, supports many-to-many matching by allowing an image region to be matched to multiple phrases and vice versa. We show competitive performance on the Flickr30K benchmark dataset and, through ablation studies, validate the efficacy of sequential grounding as well as individual design choices in our model architecture.