Corrective 3D Reconstruction of Lips from Monocular Video
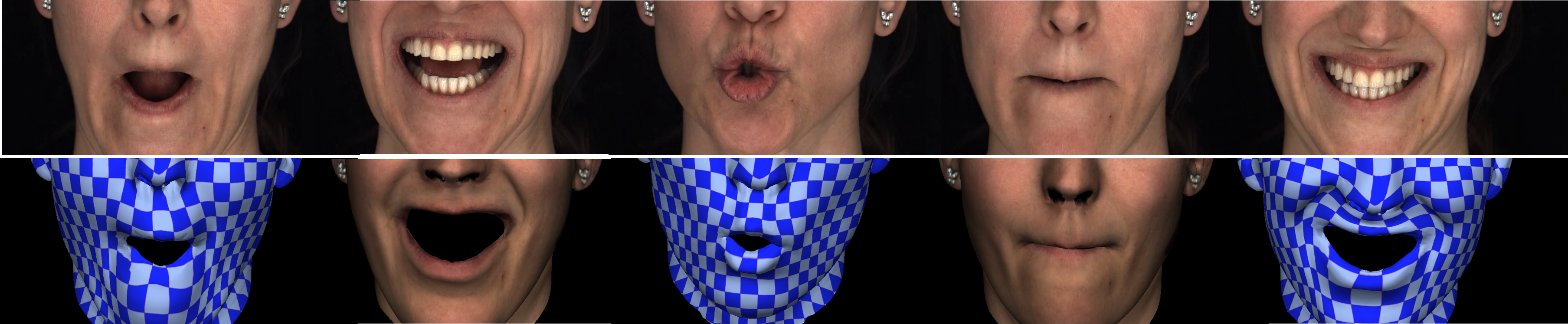
We quantitatively and qualitatively show that our monocular approach reconstructs higher quality lip shapes, even for complex shapes like a kiss or lip rolling than previous monocular approaches.
November 11, 2016
ACM SIGGRAPH Asia 2016
Authors
Pablo Garrido (Max Planck Institute for Informatics)
Michael Zollhöfer (Max Planck Institute for Informatics)
Chenglei Wu (ETH Zurich)
Derek Bradley (Disney Research)
Patrick Pérez (Technicolor)
Thabo Beeler (Disney Research)
Christian Theobalt (Max Planck Institute for Informatics)

Corrective 3D Reconstruction of Lips from Monocular Video
In facial animation, the accurate shape and motion of the lips of virtual humans is of paramount importance, since subtle nuances in mouth expression strongly influence the interpretation of speech and the conveyed emotion. Unfortunately, passive photometric reconstruction of expressive lip motions, such as a kiss or rolling lips, is fundamentally hard even with multi-view methods in controlled studios. To alleviate this problem, we present a novel approach for fully automatic reconstruction of detailed and expressive lip shapes along with the dense geometry of the entire face, from just monocular RGB video. To this end, we learn the difference between inaccurate lip shapes found by a state-of-the-art monocular facial performance capture approach, and the true 3D lip shapes reconstructed using a high-quality multi-view system in combination with applied lip tattoos that are easy to track. A robust gradient domain regressor is trained to infer accurate lip shapes from coarse monocular reconstructions, with the additional help of automatically extracted inner and outer 2D lip contours. We quantitatively and qualitatively show that our monocular approach reconstructs higher quality lip shapes, even for complex shapes like a kiss or lip rolling than previous monocular approaches. Furthermore, we compare the performance of person-specific and multi-person generic regression strategies and show that our approach generalizes to new individuals and general scenes, enabling high-fidelity reconstruction even from commodity video footage.