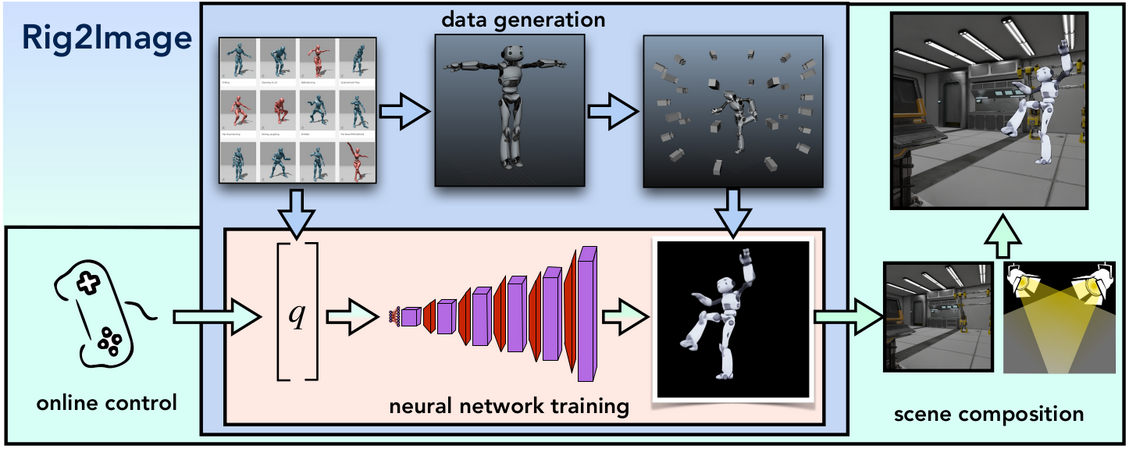
Rig-space Neural Rendering
Our idea is to render the character in many different poses and views, and to train a deep neural network to render high resolution images, from the rig parameters directly.
Marc 24, 2020
arxiv.org
Authors
Dominik Borer (DisneyResearch|Studios/ETH Joint PhD)
Lu Yuhang (ETH Zurich)
Laura Wuelfroth (ETH Zurich)
Jakob Buhmann (DisneyResearch|Studios)
Martin Guay (DisneyResearch|Studios)
Rig-space Neural Rendering
Movie productions use high resolution 3d characters with complex proprietary rigs to create the highest quality images possible for large displays. Unfortunately, these 3d assets are typically not compatible with real-time graphics engines used for games, mixed reality and real-time pre-visualization. Consequently, the 3d characters need to be re-modeled and re-rigged for these new applications, requiring weeks of work and artistic approval. Our solution to this problem is to learn a compact image-based rendering of the original 3d character, conditioned directly on the rig parameters. Our idea is to render the character in many different poses and views, and to train a deep neural network to render high resolution images, from the rig parameters directly. Many neural rendering techniques have been proposed to render from 2d skeletons, or geometry and UV maps. However these require additional steps to create the input structure (e.g. a low res mesh), often hold ambiguities between front and back (e.g. 2d skeletons) and most importantly, do not preserve the animator’s workflow of manipulating specific type of rigs, as well as the real-time game engine pipeline of interpolating rig parameters. In contrast, our model learns to render an image directly from the rig parameters at a high resolution. We extend our architecture to support dynamic re-lighting and composition with other objects in the scene. By generating normals, depth, albedo and a mask, we can produce occlusion depth tests and lighting effects through the normals.