CLIP-Fusion: A Spatio-Temporal Quality Metric for Frame Interpolation
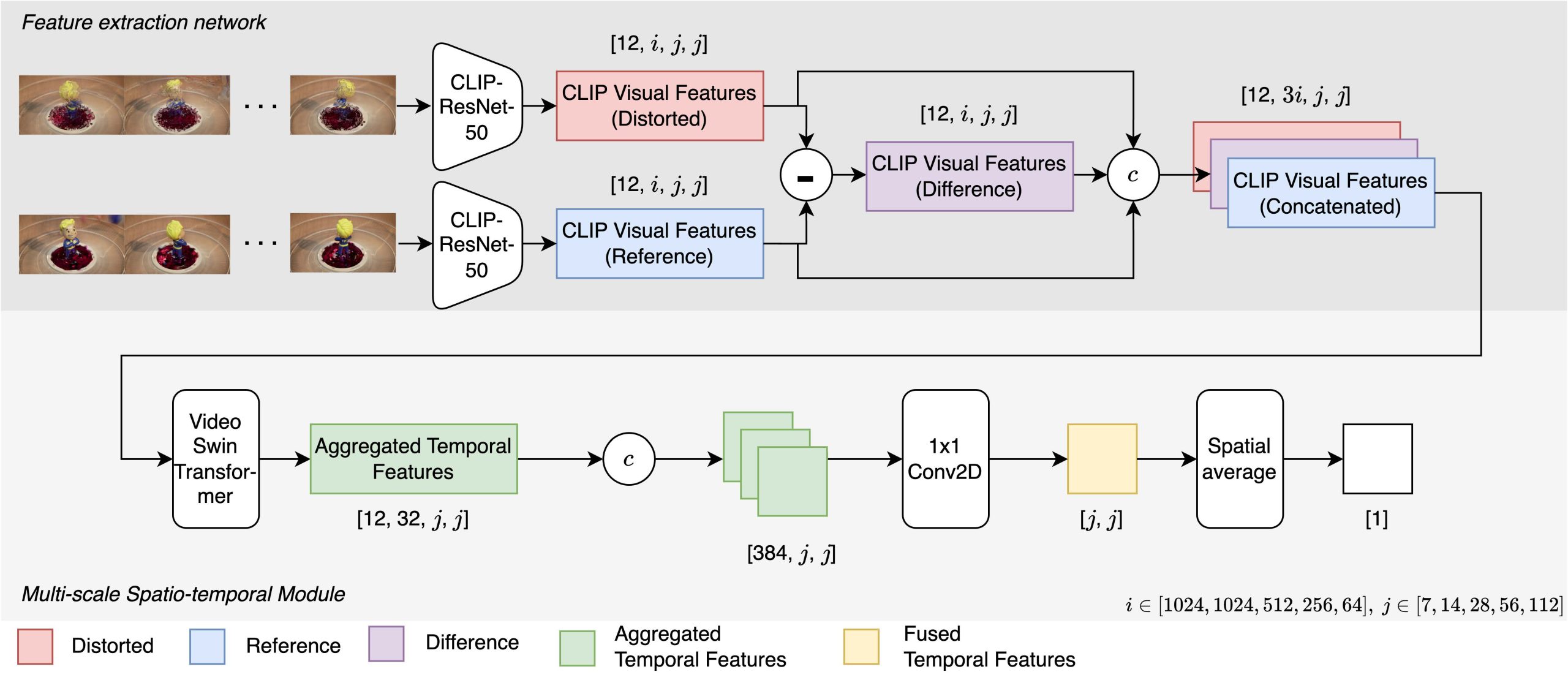
In this paper, we aim to leverage semantic feature extraction capabilities of the pre-trained visual backbone of CLIP. Specifically, we adapt its multi-scale approach to our feature extraction network and combine it with the spatio-temporal attention mechanism of the Video Swin Transformer.
Authors
Göksel Mert Çökmez (ETH Zurich)
Yang Zhang (DisneyResearch|Studios)
Christopher Schroers (DisneyResearch|Studios)
Tunç Ozan Aydin (DisneyResearch|Studios)

CLIP-Fusion: A Spatio-Temporal Quality Metric for Frame Interpolation
Video frame interpolation (VFI) is an ill-posed problem, and a wide variety of methods have been proposed, ranging from more traditional computer vision strategies to the most recent developments with neural network models. Although there are many methods to interpolate video frames, quality assessment regarding the resulting artifacts from these methods remains dependent on off-the-shelf methods. Although these methods can make accurate quality predictions for many visual artifacts such as compression, blurring, and banding, their performance is mediocre for VFI artifacts due to the unique spatio-temporal qualities of such artifacts. To address this, we aim to leverage semantic feature extraction capabilities of the pre-trained visual backbone of CLIP. Specifically, we adapt its multi-scale approach to our feature extraction network and combine it with the spatio-temporal attention mechanism of the Video Swin Transformer. This allows our model to detect interpolation-related artifacts across frames and predict the relevant differential mean opinion score. Our model outperforms existing state-of-the-art quality metrics for assessing the quality of interpolated frames in both full-reference (FR) and no-reference (NR) settings.