Joint Learning of Depth and Appearance for Portrait Images
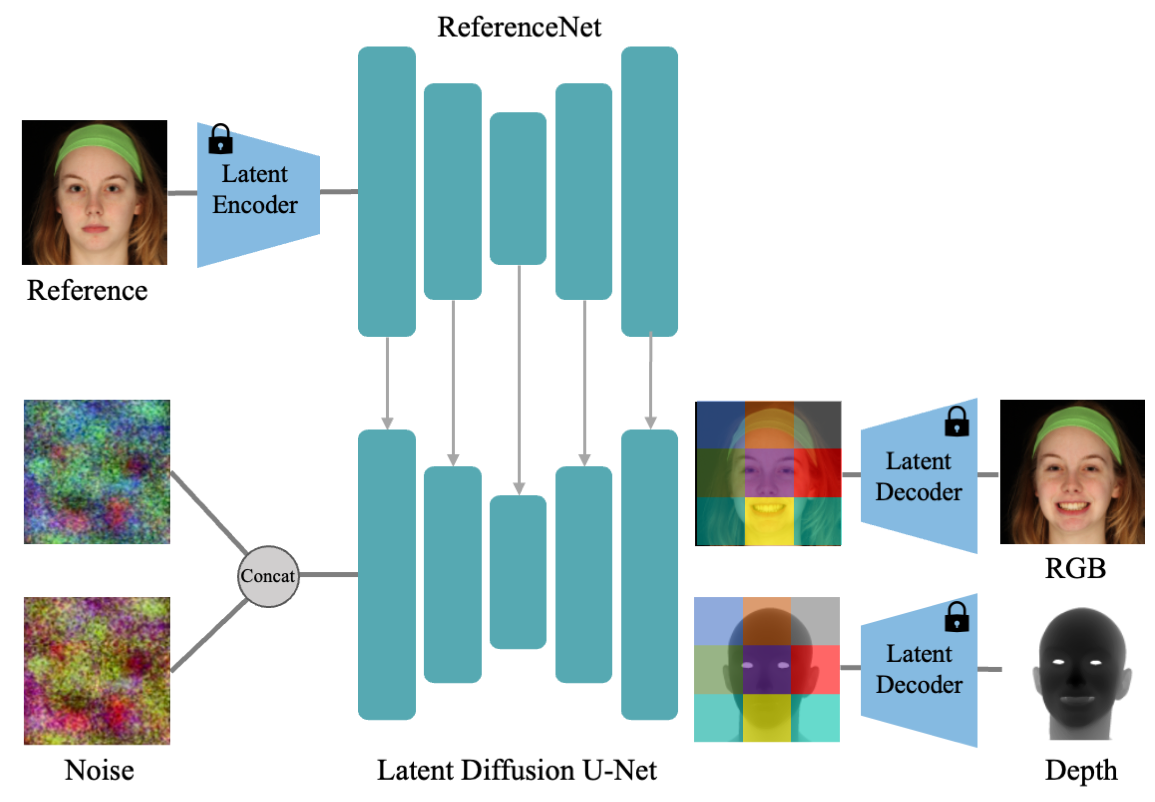
In this work, we propose to jointly learn the visual appearance and depth of faces simultaneously in a diffusion-based portrait image generator. Our method embraces the end-to-end diffusion paradigm and introduces a new architecture suitable for learning this joint distribution, consisting of a reference network for target identity and a channel expanded diffusion backbone.
October 18, 2025
Workshop on Human-Interactive Generation and Editing (2025)
Authors
Xinya Ji (ETH Zurich, Nanjing University)
Gaspard Zoss (DisneyResearch|Studios)
Prashanth Chandran (DisneyResearch|Studios)
Lingchen Yang (ETH Zurich)
Xun Cao (Nanjing University)
Barbara Solenthaler (ETH Zurich)
Derek Bradley (DisneyResearch|Studios)

Joint Learning of Depth and Appearance for Portrait Images
The field of 2D portrait manipulation has experienced significant advancements in recent years. A lot of research has leveraged the prior knowledge embedded in large generative diffusion models to enable high-quality image editing and animation tasks. However, most generative methods only focus on creating RGB images as output, and the co-generation of consistent visual plus 3D output remains largely under-explored. In our work, we propose to jointly learn the visual appearance and depth of faces simultaneously in a diffusion-based portrait image generator. Our method embraces the end-to-end diffusion paradigm and introduces a new architecture suitable for learning this joint distribution, consisting of a reference network for target identity and a channel expanded diffusion backbone. We extend the training objective to predict both RGB and depth from a single representation, enabling various applications such as joint generation, facial depth estimation, and depth-driven portrait manipulation. Our experiments demonstrate that joint learning not only surpasses separate conditional generation but also achieves state-of-the-art results on both facial depth estimation and portrait image animation, validating the benefit of a joint-learning approach for depth and appearance of portrait images.