by America Ortiz | Oct 18, 2025 | Capture, VFX, Visual Computing
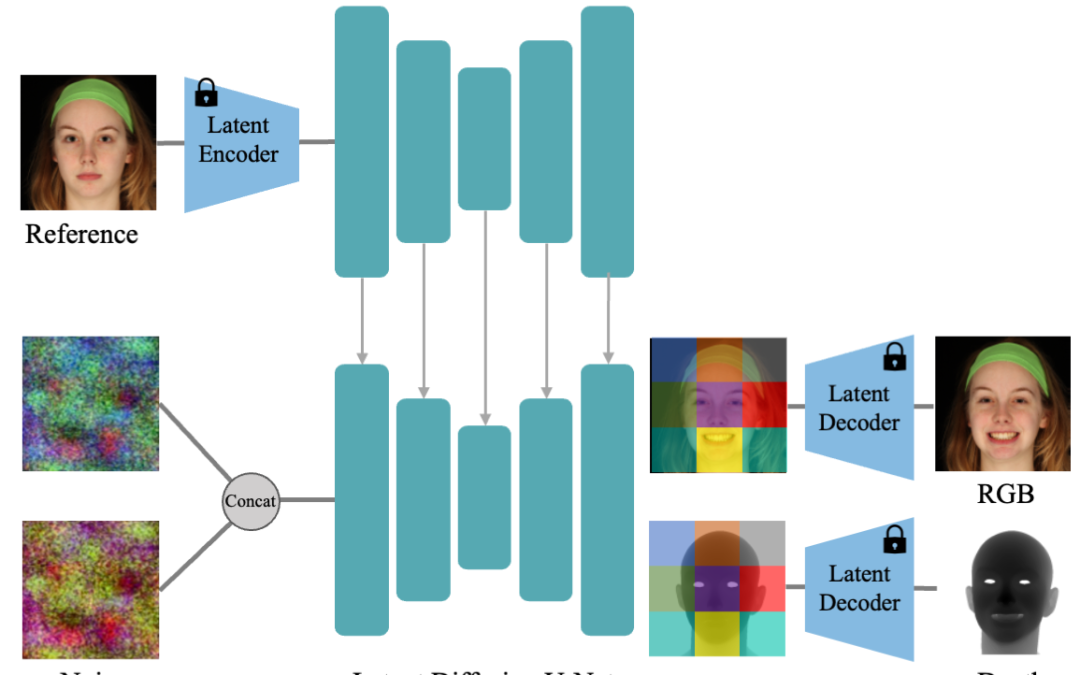
Joint Learning of Depth and Appearance for Portrait Images In this work, we propose to jointly learn the visual appearance and depth of faces simultaneously in a diffusion-based portrait image generator. Our method embraces the end-to-end diffusion paradigm and...

by America Ortiz | Oct 16, 2025 | Video Processing, Visual Computing
LDIP: Long Distance Information Propagation for Video Super-Resolution In this work, we propose a strategy for long distance information propagation with a flexible fusion module that can optionally also assimilate information from additional high resolution reference...

by America Ortiz | Oct 16, 2025 | Capture, VFX, Visual Computing
Monocular Facial Appearance Capture in the Wild In this work, we present a new method for reconstructing the appearance properties of human faces from a lightweight capture procedure in an unconstrained environment. October 16, 2025International Conference on Computer...

by America Ortiz | Oct 7, 2025 | Video Processing, Visual Computing
Leveraging Diffusion Models for Stylization using Multiple Style Images In this work, we propose leveraging multiple style images which helps better represent style features and prevent content leaking from the style images. We design a method that leverages both...

by America Ortiz | Sep 29, 2025 | Video Processing, Visual Computing
ReBaIR: Reference-Based Image Restoration In this work, we propose a novel and generic reference-based restoration method that is applicable to any model and any task. We start with the observation that restoration models typically operate in feature space before a...