
by America Ortiz | Jul 16, 2025 | Machine Learning, Video Processing, Visual Computing
Reenact Anything: Semantic Video Motion Transfer Using Motion-Textual Inversion In this work, we propose motion-textual inversion, a general method to transfer the semantic motion of a given reference motion video to given target images. It generalizes across various...
by America Ortiz | Jul 16, 2025 | Video Processing, Visual Computing
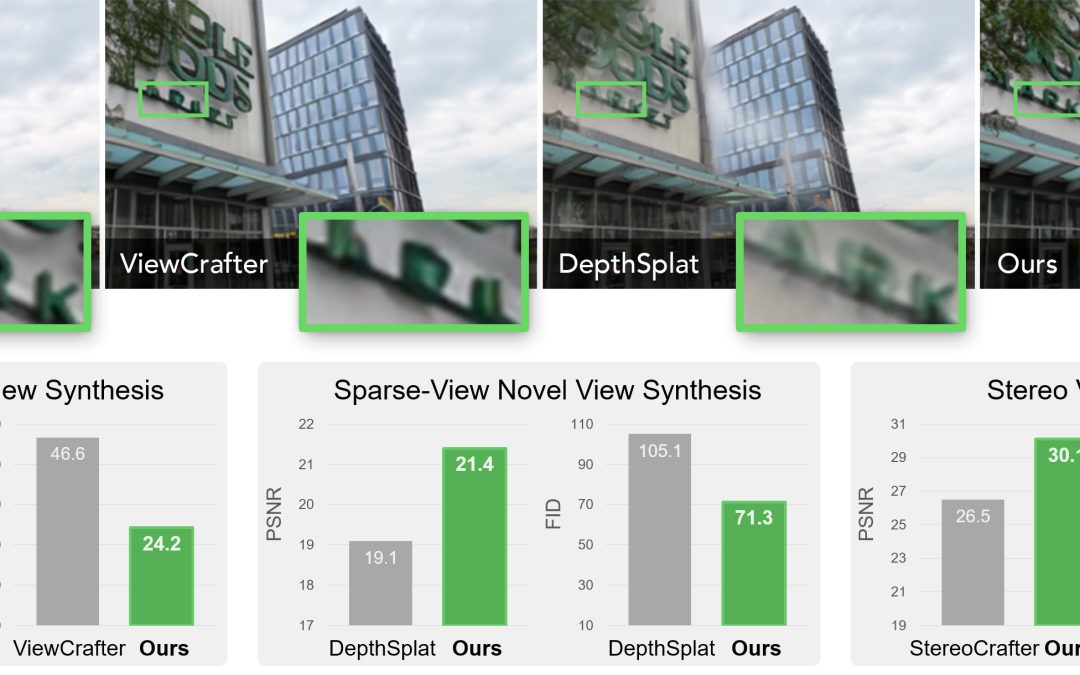
High-Fidelity Novel View Synthesis via Splatting-Guided Diffusion In this paper, we propose an aligned synthesis strategy for precise control of target viewpoints and geometry-consistent view synthesis. To mitigate texture hallucination, we design a texture bridge...
by America Ortiz | Jul 9, 2025 | Capture, VFX, Visual Computing
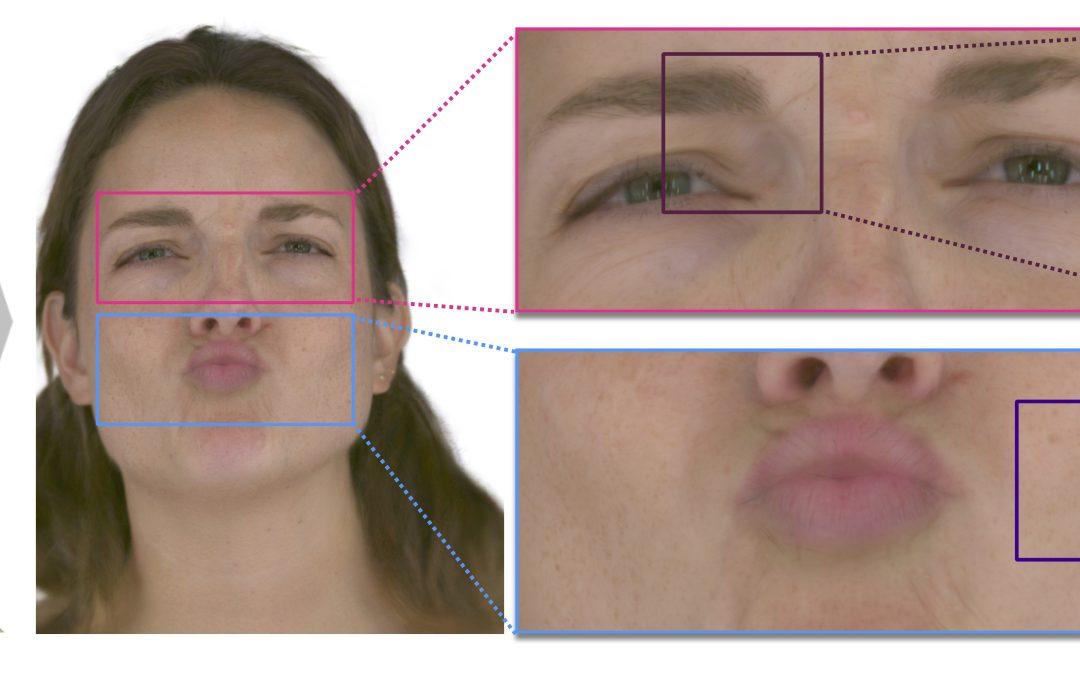
ScaffoldAvatar: High-Fidelity Gaussian Avatars with Patch Expressions In this work, we propose to couple locally-defined facial expressions with 3D Gaussian splatting to enable creating ultra-high fidelity, expressive and photorealistic head avatars. July 10,...

by America Ortiz | Jun 9, 2025 | Animation, Visual Computing
LookingGlass: Generative Anamorphoses via Laplacian Pyramid Warping In this work, we revisit these famous optical illusions with a generative twist. With the help of latent rectified flow models, we propose a method to create anamorphic images that still retain a...

by America Ortiz | Jun 9, 2025 | Video Processing, Visual Computing
Bridging the Gap between Diffusion Models and Universal Quantization for Image Compression In this paper, we propose a novel quantization based forward diffusion process with theoretical foundations that tackles all three aforementioned gaps. We achieve this through...