
by America Ortiz | May 31, 2026 | Capture, VFX, Visual Computing
RelightAnyone: A Generalized Relightable 3D Gaussian Head Model In this work, we propose a new generalized relightable 3D Gaussian head model that can relight any subject observed in a single- or multi-view images without requiring OLAT data for that subject. May 31,...
by America Ortiz | Apr 22, 2026 | Capture, VFX, Visual Computing
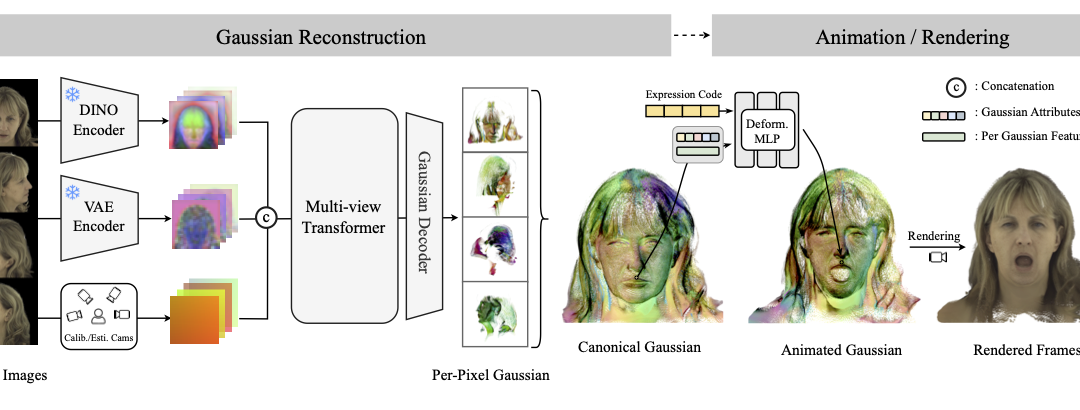
FastGHA: Generalized Few-Shot 3D Gaussian Head Avatars with Real-Time Animation In this work, we extend the explicit Gaussian representations with per-Gaussian features and introduce a lightweight MLP-based dynamic network to predict 3D Gaussian deformations from...
by America Ortiz | Apr 4, 2026 | Capture, Machine Learning, VFX
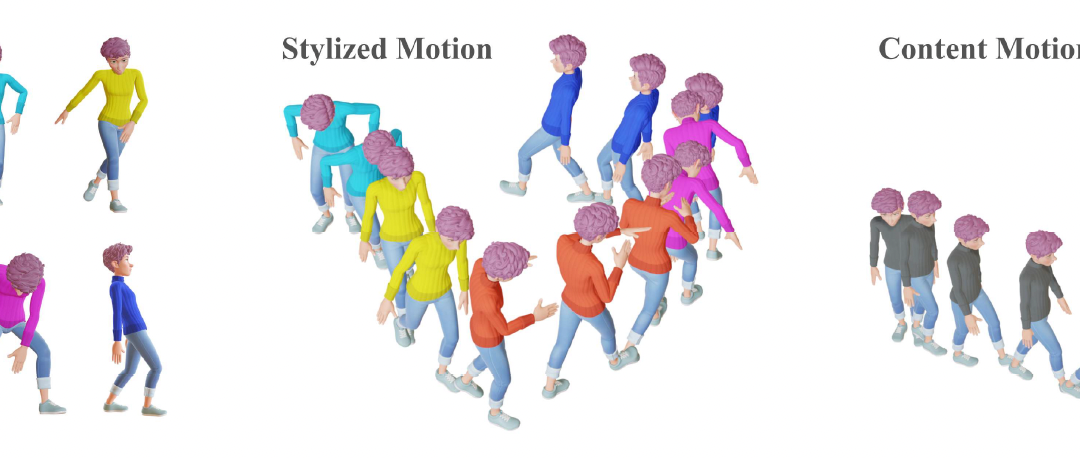
VQ-Style: Disentangling Style and Content in Motion with Residual Quantized Representations In this work, we propose a novel method for effective disentanglement of the style and content in human motion data to facilitate style transfer. April 4, 2026 Eurographics...

by America Ortiz | Apr 4, 2026 | Capture, Machine Learning, VFX
CANRIG: Cross-Attention Neural Face Rigging with Variable Local Control In this work, we introduce CANRig, a fully automated neural facial rigging approach that simplifies the process of creating and editing facial poses by benefiting from global correlations learned...

by America Ortiz | Dec 3, 2025 | Capture, Machine Learning, VFX
Implicit Bézier Motion Model for Precise Spatial and Temporal Control In this work, we introduce a new Implicit Bézier Motion Model (IBMM), which during training is exposed to all possible configurations of control points, enabling control at arbitrary timings. This...

by America Ortiz | Oct 26, 2025 | Capture, VFX, Visual Computing
Multimodal Conditional 3D Face Geometry Generation In this work, we present a new method for multimodal conditional 3D face geometry generation that allows user-friendly control over the output identity and expression via a number of different conditioning signals...