by America Ortiz | Apr 22, 2026 | Capture, VFX, Visual Computing
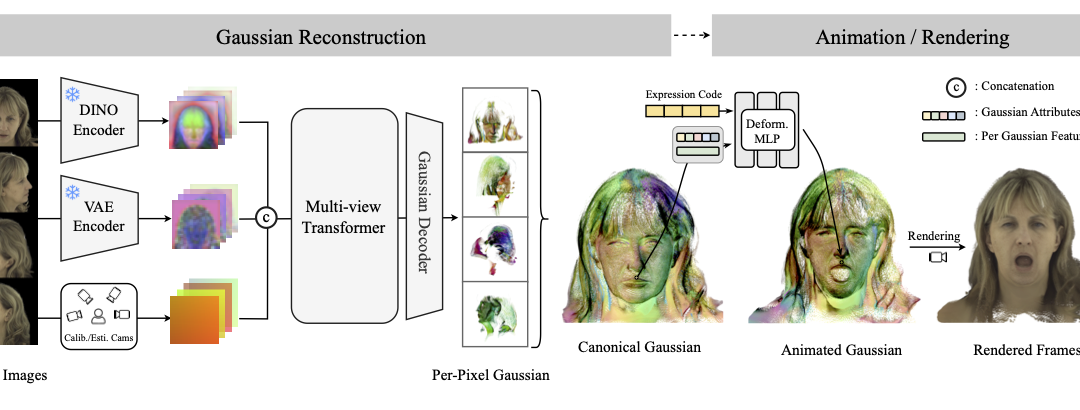
FastGHA: Generalized Few-Shot 3D Gaussian Head Avatars with Real-Time Animation In this work, we extend the explicit Gaussian representations with per-Gaussian features and introduce a lightweight MLP-based dynamic network to predict 3D Gaussian deformations from...

by America Ortiz | Apr 4, 2026 | Capture, Machine Learning, VFX
CANRIG: Cross-Attention Neural Face Rigging with Variable Local Control In this work, we introduce CANRig, a fully automated neural facial rigging approach that simplifies the process of creating and editing facial poses by benefiting from global correlations learned...
by America Ortiz | Apr 4, 2026 | Capture, Machine Learning, VFX
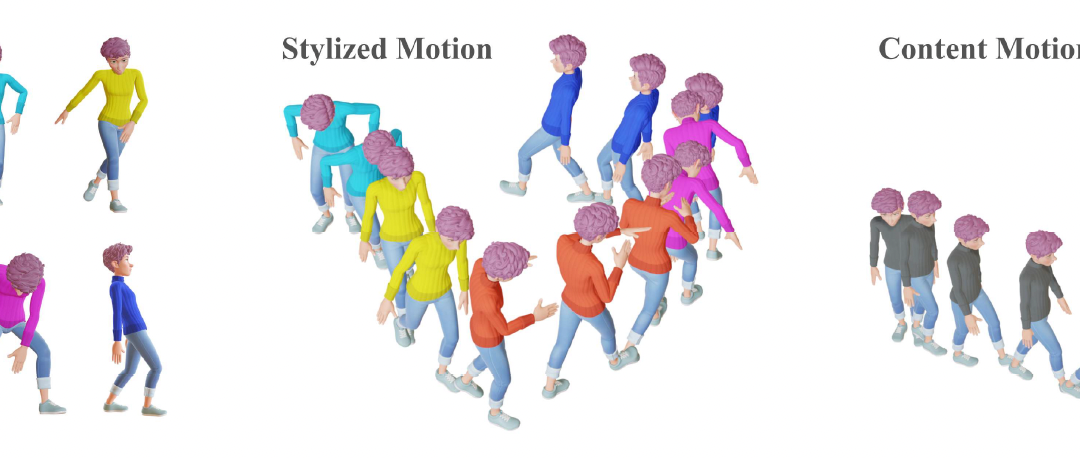
VQ-Style: Disentangling Style and Content in Motion with Residual Quantized Representations In this work, we propose a novel method for effective disentanglement of the style and content in human motion data to facilitate style transfer. April 4, 2026 Eurographics...
by America Ortiz | Dec 15, 2025 | Rendering, Video Processing, Visual Computing
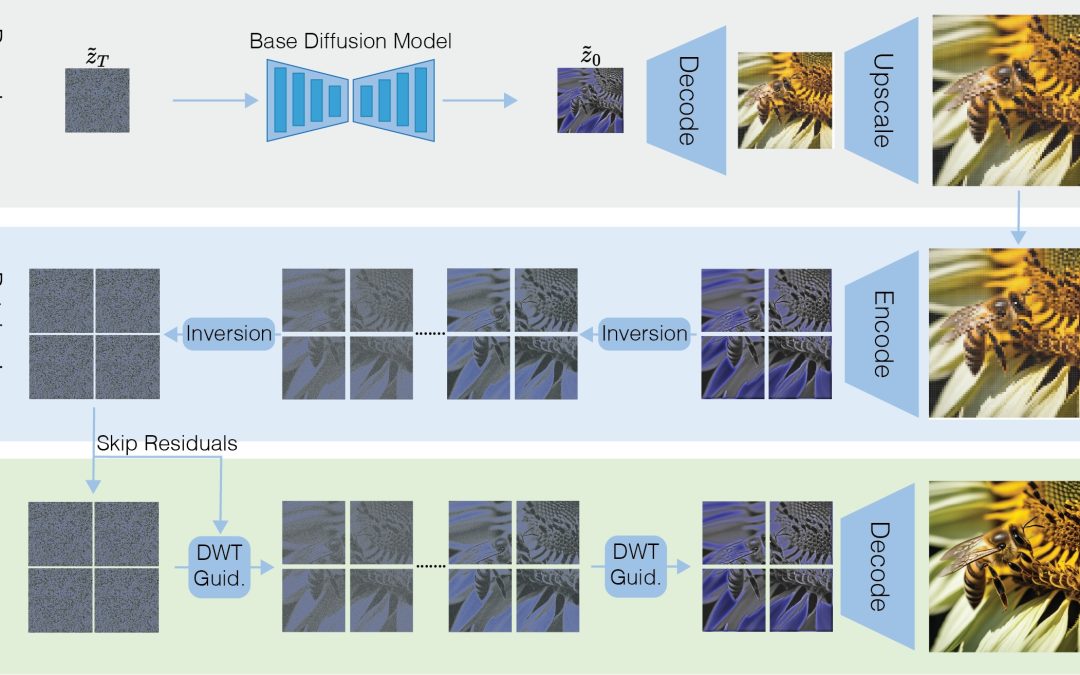
HiWave: Training-Free High-Resolution Image Generation via Wavelet-Based Diffusion Sampling In this paper, we introduce HiWave, a training-free, zero-shot approach that substantially enhances visual fidelity and structural coherence in ultra-high-resolution image...

by America Ortiz | Dec 14, 2025 | Animation, Visual Computing
Shaping Strands with Neural Style Transfer In this paper we propose the first stylization pipeline to support hair and fur. Through a carefully tailored fur/hair representation, our approach allows complex, 3D consistent and temporally coherent grooms that are...