by America Ortiz | Dec 15, 2025 | Rendering, Video Processing, Visual Computing
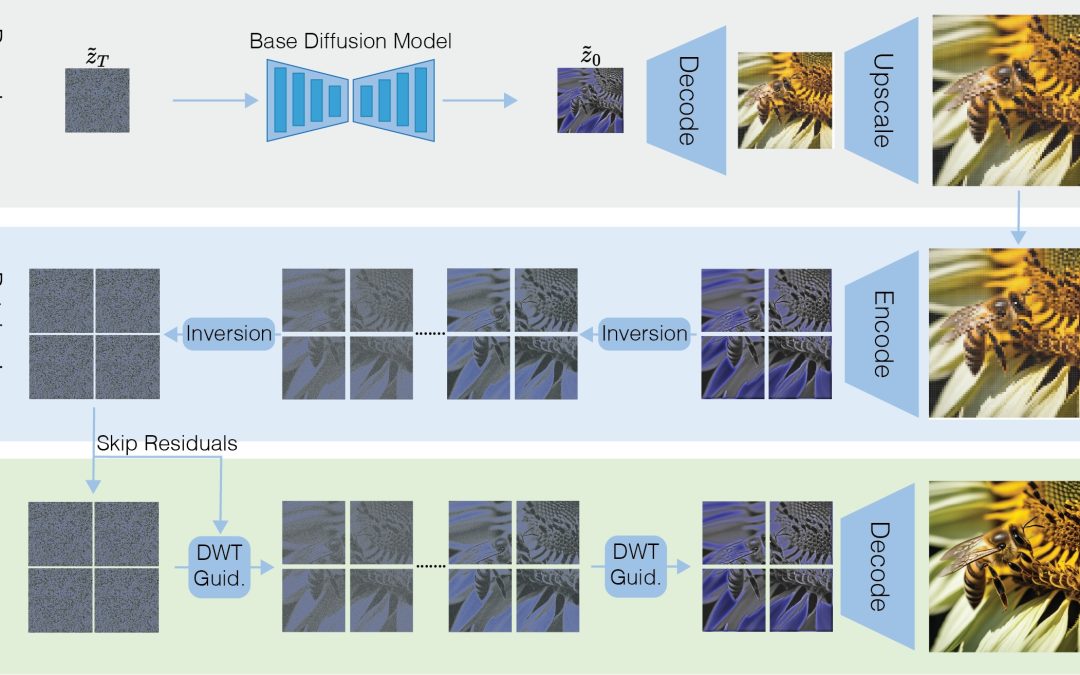
HiWave: Training-Free High-Resolution Image Generation via Wavelet-Based Diffusion Sampling In this paper, we introduce HiWave, a training-free, zero-shot approach that substantially enhances visual fidelity and structural coherence in ultra-high-resolution image...

by America Ortiz | Dec 14, 2025 | Animation, Visual Computing
Shaping Strands with Neural Style Transfer In this paper we propose the first stylization pipeline to support hair and fur. Through a carefully tailored fur/hair representation, our approach allows complex, 3D consistent and temporally coherent grooms that are...

by America Ortiz | Dec 7, 2025 | Video Processing, Visual Computing
Spatiotemporal Diffusion Priors for Extreme Video Compression In this paper, we propose to extend this paradigm to video compression by utilizing a generative spatiotemporal prior and present the first codec based on a video diffusion model. December 7, 2025Picture...

by America Ortiz | Dec 3, 2025 | Capture, Machine Learning, VFX
Implicit Bézier Motion Model for Precise Spatial and Temporal Control In this work, we introduce a new Implicit Bézier Motion Model (IBMM), which during training is exposed to all possible configurations of control points, enabling control at arbitrary timings. This...

by America Ortiz | Oct 26, 2025 | Capture, VFX, Visual Computing
Multimodal Conditional 3D Face Geometry Generation In this work, we present a new method for multimodal conditional 3D face geometry generation that allows user-friendly control over the output identity and expression via a number of different conditioning signals...