
by America Ortiz | Dec 3, 2025 | Capture, Machine Learning, VFX
Implicit Bézier Motion Model for Precise Spatial and Temporal Control In this work, we introduce a new Implicit Bézier Motion Model (IBMM), which during training is exposed to all possible configurations of control points, enabling control at arbitrary timings. This...

by America Ortiz | Oct 26, 2025 | Capture, VFX, Visual Computing
Multimodal Conditional 3D Face Geometry Generation In this work, we present a new method for multimodal conditional 3D face geometry generation that allows user-friendly control over the output identity and expression via a number of different conditioning signals...
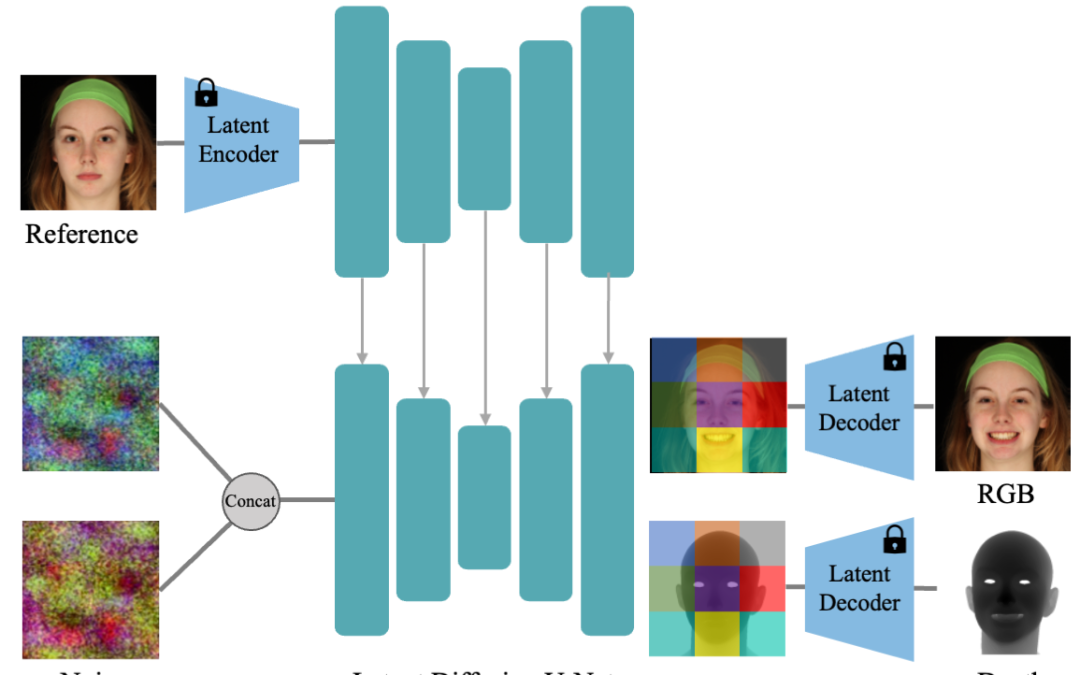
by America Ortiz | Oct 18, 2025 | Capture, VFX, Visual Computing
Joint Learning of Depth and Appearance for Portrait Images In this work, we propose to jointly learn the visual appearance and depth of faces simultaneously in a diffusion-based portrait image generator. Our method embraces the end-to-end diffusion paradigm and...

by America Ortiz | Oct 16, 2025 | Video Processing, Visual Computing
LDIP: Long Distance Information Propagation for Video Super-Resolution In this work, we propose a strategy for long distance information propagation with a flexible fusion module that can optionally also assimilate information from additional high resolution reference...

by America Ortiz | Oct 16, 2025 | Capture, VFX, Visual Computing
Monocular Facial Appearance Capture in the Wild In this work, we present a new method for reconstructing the appearance properties of human faces from a lightweight capture procedure in an unconstrained environment. October 16, 2025International Conference on Computer...